aliases:
- large language models
tags:
- LLM
- deep_learning
- embedding
- generative
- interpretability
- multimodal
- AI_generated
- MistralTechnical Overview of Large Language Models
Definition
Large Language Models (LLMs) are advanced artificial intelligence systems designed to understand, generate, and interact with human language. These models are trained on vast amounts of text data to capture the nuances of language, enabling them to perform a wide range of natural language processing (NLP) tasks such as text generation, translation, summarization, and question answering.
High-Level Overview
LLMs are typically built using deep learning techniques, particularly transformer architectures. They are trained on massive datasets containing billions of words to learn the statistical patterns and structures of language. The training process involves feeding the model large amounts of text and adjusting its parameters to minimize the difference between its predictions and the actual text.
Key components of LLMs include:
- embedding Layer: Converts input text into numerical vectors.
- Transformer Layers: Process these vectors through multiple layers of self-attention and feed-forward neural networks.
- Output Layer: Generates the final text output based on the processed vectors.
Top 3 Most Popular Architectures
-
Transformer Architecture
- Description: Introduced by Vaswani et al. in 2017, the transformer architecture uses self-attention mechanisms to weigh the importance of different words in a sentence. It consists of an encoder and a decoder, both made up of stacked layers of self-attention and feed-forward networks.
- Popular Models: BERT (Bidirectional Encoder Representations from Transformers), RoBERTa, T5 (Text-to-Text Transfer Transformer).
-
BERT (Bidirectional Encoder Representations from Transformers)
- Description: Developed by Google, BERT is designed to understand the context of a word by looking at both the left and right sides of the word. It is pre-trained on a large corpus of text and can be fine-tuned for specific NLP tasks.
- Applications: Text classification, named entity recognition, question answering.
-
T5 (Text-to-Text Transfer Transformer)
- Description: Also developed by Google, T5 frames all NLP tasks as text-to-text problems. It uses a unified architecture where both the input and output are text, making it highly versatile.
- Applications: Machine translation, summarization, text generation.
Tools Based on LLMs
-
Hugging Face Transformers library
- Description: An open-source library by Hugging Face that provides pre-trained models for various NLP tasks. It supports a wide range of transformer architectures and allows for easy fine-tuning and deployment.
- Features: Pre-trained models, tokenizers, fine-tuning capabilities, integration with popular ML frameworks like PyTorch and Tensorflow.
-
Google's BERT and T5
- Description: Google offers pre-trained BERT and T5 models that can be fine-tuned for specific tasks. These models are available through TensorFlow and PyTorch libraries.
- Features: Pre-trained models, fine-tuning scripts, integration with Google Cloud services.
-
Microsoft's Turing-NLG
- Description: Microsoft's Turing Natural Language Generation (Turing-NLG) is a large language model designed for generating human-like text. It is one of the largest models available, with billions of parameters.
- Features: High-quality text generation, integration with Azure services, support for various NLP tasks.
Optimizing Large Language Models
Optimizing Large Language Models (LLMs) is crucial for enhancing their performance, efficiency, and applicability to specific tasks. Several techniques are employed to achieve this, including prompt engineering, Retrieval-Augmented Generation (RAG), and fine-tuning.
Prompt Engineering
Definition: Prompt Engineering involves crafting specific input prompts to guide the model's output more effectively. By carefully designing the input, users can influence the model to generate more relevant and contextually appropriate responses.
Techniques:
- Zero-Shot Learning: Providing the model with a clear and concise prompt that describes the task without any examples.
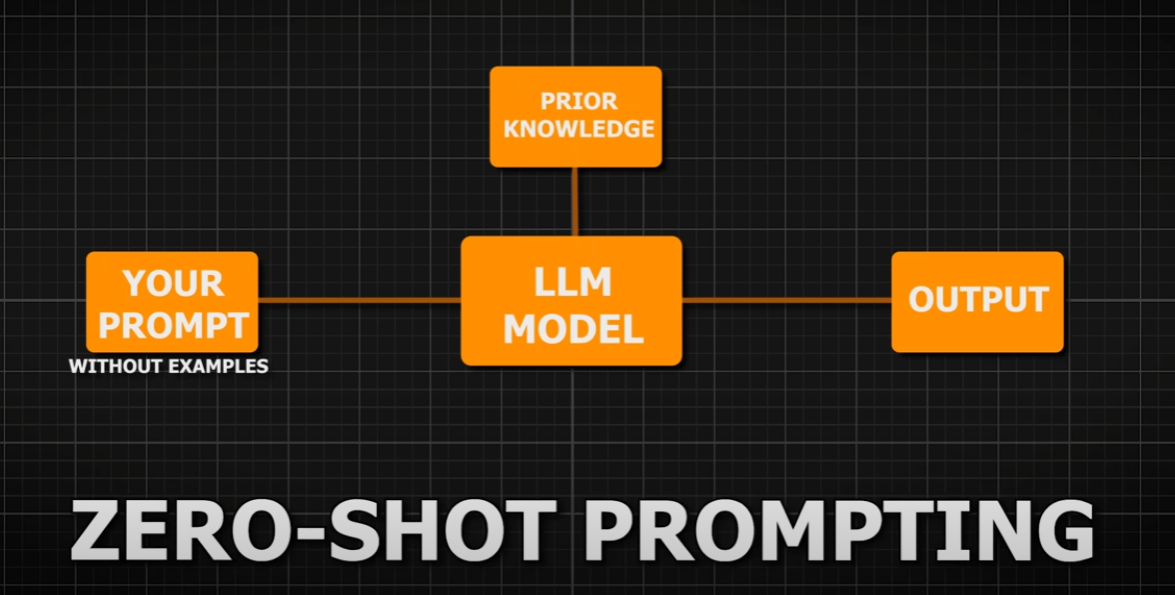
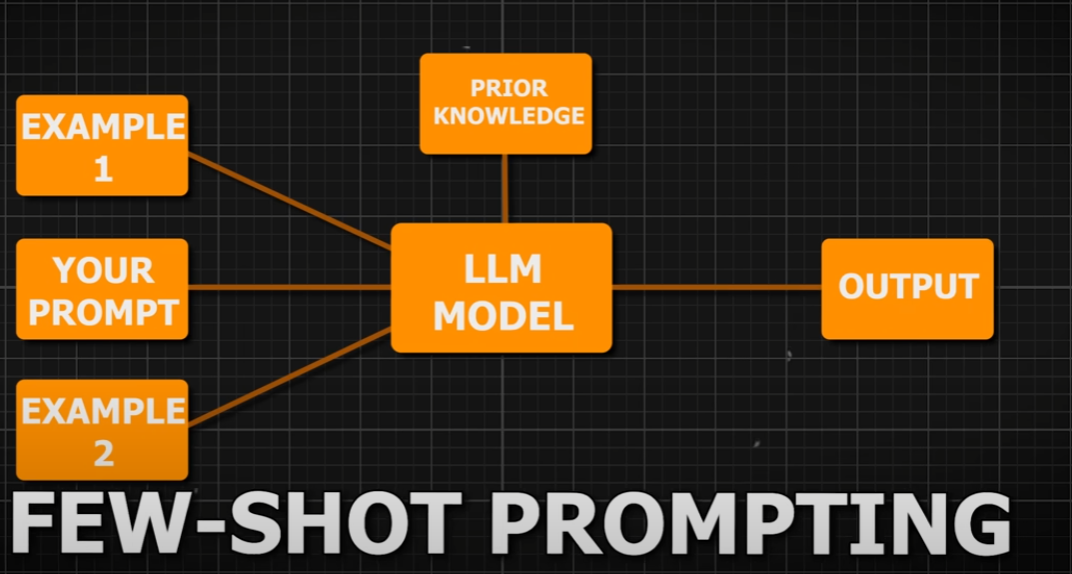
- Few-Shot Learning: Including a few examples in the prompt to help the model understand the task better.
- Chain-of-Thought Prompting: Breaking down complex tasks into smaller, manageable steps within the prompt to guide the model through the reasoning process.
Applications:
- Improving the relevance and coherence of generated text.
- Enhancing the model's performance on specific tasks without additional training.
Retrieval-Augmented Generation (RAG)
Definition: RAG combines the strengths of retrieval-based methods and generative models. It involves retrieving relevant documents or information from a large corpus and using this information to augment the generation process.
Components:
- Retriever: A model that retrieves relevant documents or passages from a large corpus based on the input query.
- Generator: A language model that generates the final output using the retrieved information as additional context.
Applications:
- Enhancing the factual accuracy of generated text.
- Improving the model's performance on tasks that require external knowledge, such as question answering and summarization.
Fine-Tuning
Definition: Fine-tuning involves taking a pre-trained language model and further training it on a specific dataset to adapt it to a particular task or domain. This process adjusts the model's parameters to better capture the nuances of the target task.
Techniques:
- Task-Specific Fine-Tuning: Training the model on a labeled dataset specific to the task, such as sentiment analysis or named entity recognition.
- Domain-Specific Fine-Tuning: Training the model on a dataset from a specific domain, such as medical or legal texts, to improve its performance in that domain.
Applications:
- Improving the model's performance on specialized tasks and domains.
- Adapting the model to new or emerging areas where pre-trained models may not perform well.
Conclusion
Optimizing Large Language Models through prompt engineering, Retrieval-Augmented Generation (RAG), and fine-tuning can significantly enhance their performance and applicability.
Prompt engineering allows for more controlled and relevant outputs, RAG improves factual accuracy and contextual understanding, and fine-tuning adapts the model to specific tasks and domains.
By leveraging these techniques, LLMs can be tailored to meet the diverse needs of various applications, from general-purpose text generation to specialized domain-specific tasks.